Improving LLM Confidence with Step-by-Step Reasoning
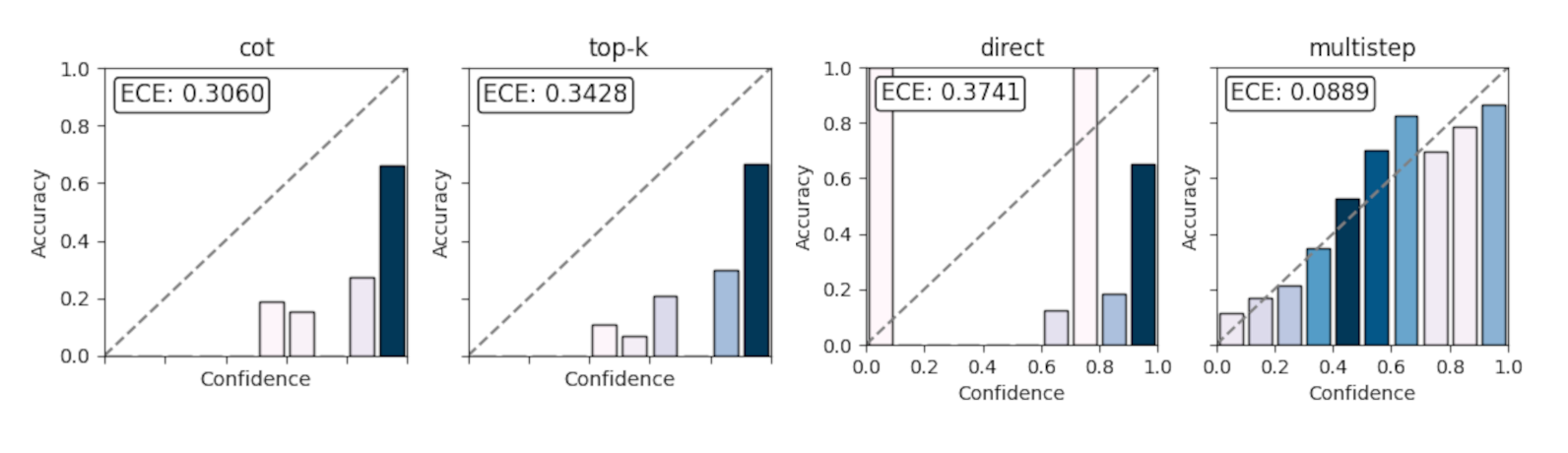
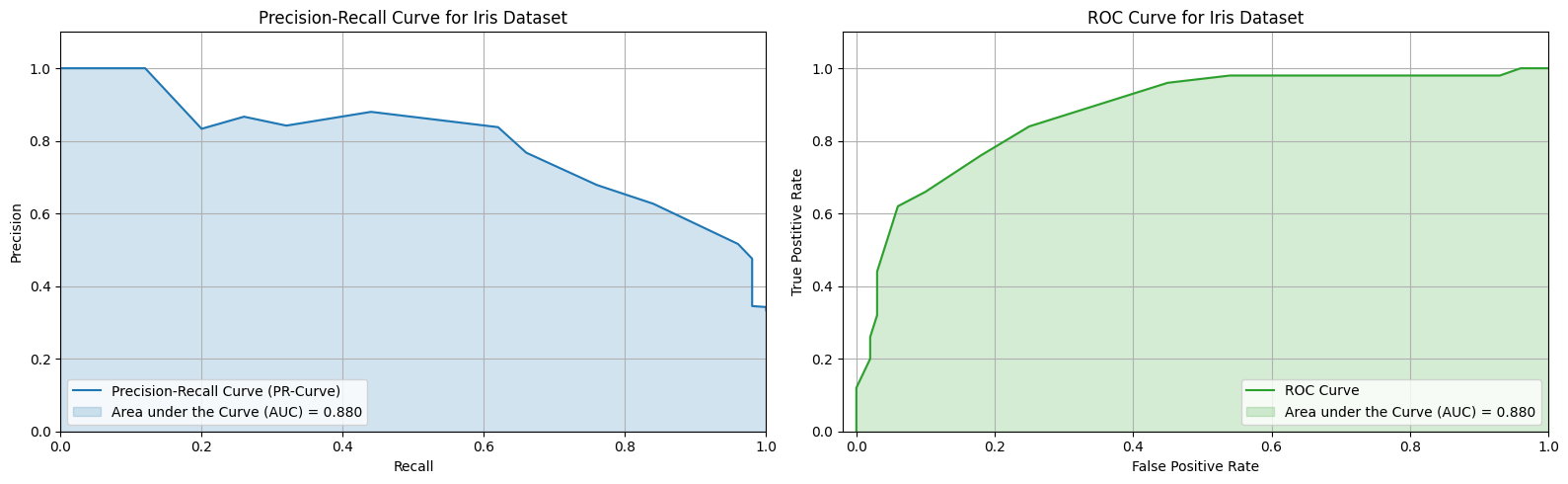
In a recent paper, “Step-wise Decomposition Improves Calibration for Answering Multi-Hop Questions”, we explore a subtle but important problem in large language models: they’re often way too confident. Even when the answer is wrong. This post walks through the core idea behind the paper, why calibration matters, and how a simple change to prompting (breaking reasoning into steps) can significantly improve how much we can trust a model’s stated confidence. ...