Introduction
As part of a university project, I was asked to create a website for the Tyrolean Alpine Journal. The project required a variety of skills I have developed throughout my education so far.
The original dataset was quite noisy, with errors introduced by OCR (image-to-text scanning), which made processing more challenging.
Project Goals
The main objectives of the project were:
- Extract location data from plain text
- Map that data to candidate geographic positions
- Use LLMs to resolve ambiguities (for example when multiple locations share the same name)
- Build an interactive website to explore the results
Data Extraction and Processing
For extracting locations, I used the well-established named entity recognition (NER) tool spaCy. From the extracted entities, I created a dataset and mapped each entry to candidate locations using the GeoNames API.
Exact matches could be transferred directly. However, partial matches or cases with multiple candidates required additional handling and were sometimes discarded.
I experimented with different approaches for resolving these ambiguities. One method involved using already validated locations as reference points and selecting the geographically closest match. Another approach filtered candidates based on Levenshtein distance. If the parsed location differed too much from any candidate, it was likely misparsed and removed.
Using LLMs for Disambiguation
The most effective method I tested was using an LLM as a judge.
The model was given the relevant text passage along with a list of candidate locations and asked to select the most likely match. It also had the option to discard all candidates if none seemed plausible.
This approach significantly improved the overall quality of the dataset.
Building the Website
After processing, all data was stored in an SQLite database. I then built an interactive website to explore the results.
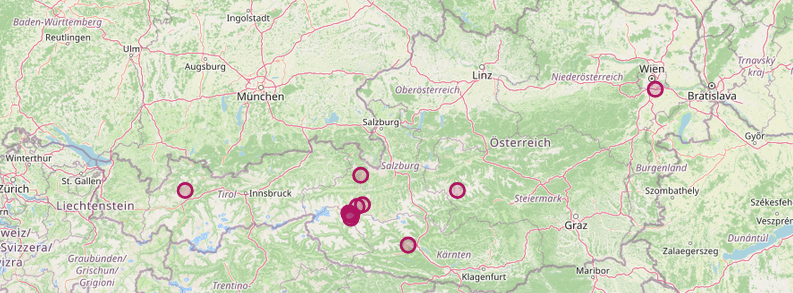
Leaflet was used as the JavaScript library to display locations on a map.
- By default, all locations for the current selection of articles are shown
- Clicking on an article filters the map to only display locations mentioned in that article
- Clicking on a location shows all articles that reference it
- Additional features like filtering and search were also implemented
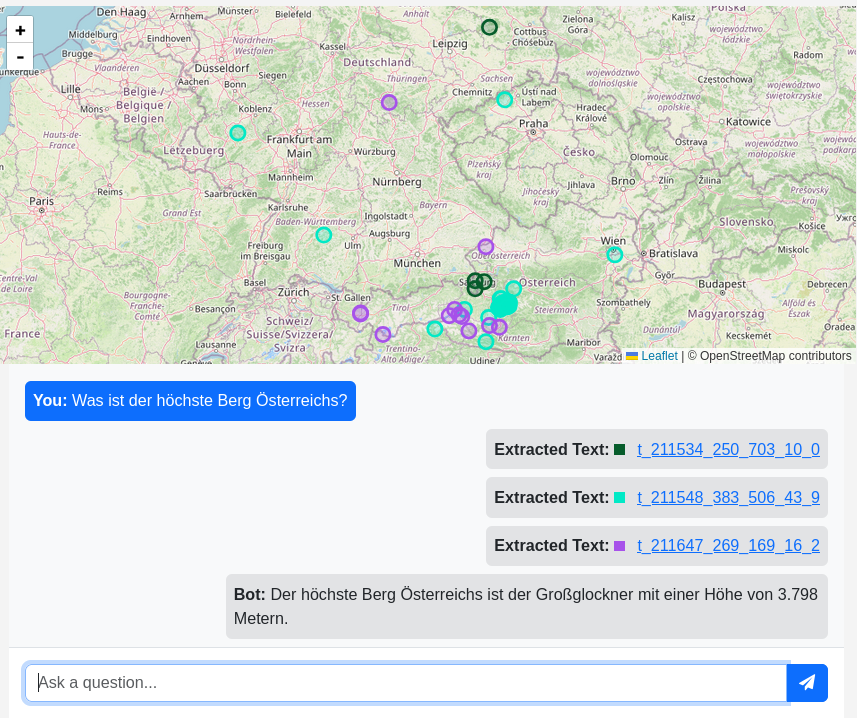
Chatbot and Semantic Search
A chatbot was also implemented as part of the project.
All articles were chunked and vectorized, and a simple RAG (retrieval-augmented generation) system was built. For a given query, it retrieves relevant articles and uses them to generate an answer.
The vector embeddings also enable semantic search instead of simple keyword matching. This is especially useful for broader or vague queries such as “first ascents”, where the exact phrasing may not appear in the text.
Conclusion
Overall, this project was the right level of challenge and a great opportunity to apply a wide range of skills.
It was my first time working with location data, and it was interesting to explore different approaches for handling ambiguity. It also showed how tools like LLMs can be used in practical and creative ways beyond simple text generation.