In a recent paper, “Step-wise Decomposition Improves Calibration for Answering Multi-Hop Questions”, we explore a subtle but important problem in large language models: they’re often way too confident.
Even when the answer is wrong.
This post walks through the core idea behind the paper, why calibration matters, and how a simple change to prompting (breaking reasoning into steps) can significantly improve how much we can trust a model’s stated confidence.
The Problem: Confidence ≠ Accuracy
Sometimes modern LLMs make mistakes. But you can just ask how confident they are.
In theory, at least.
In practice, that’s not whats happens. LLMs tend to be systematically overconfident, especially on harder tasks like multi-hop reasoning.
When this happens we call the model poorly calibrated. Calibration refers to how well a model’s predicted confidence matches reality. For example:
- If a model says “I’m 90% confident” 100 times
- It should be correct about 90 of those times
Why Multi-Hop QA Makes This Worse
Multi-hop question answering (MHQA) requires chaining together multiple facts.
Example (simplified):
“Who is the wife of the 44th US President?”
To answer this, the model needs to:
- Identify Barak Obama as the 44th president
- Know that Michelle Obama is his wife
Each step can fail independently, which throws of the final answer. Standard prompting methods (like Chain-of-Thought) typically produce:
- One final answer
- One final confidence score
That single number hides all the uncertainty in the intermediate reasoning.
The Core Idea: Multistep Reasoning
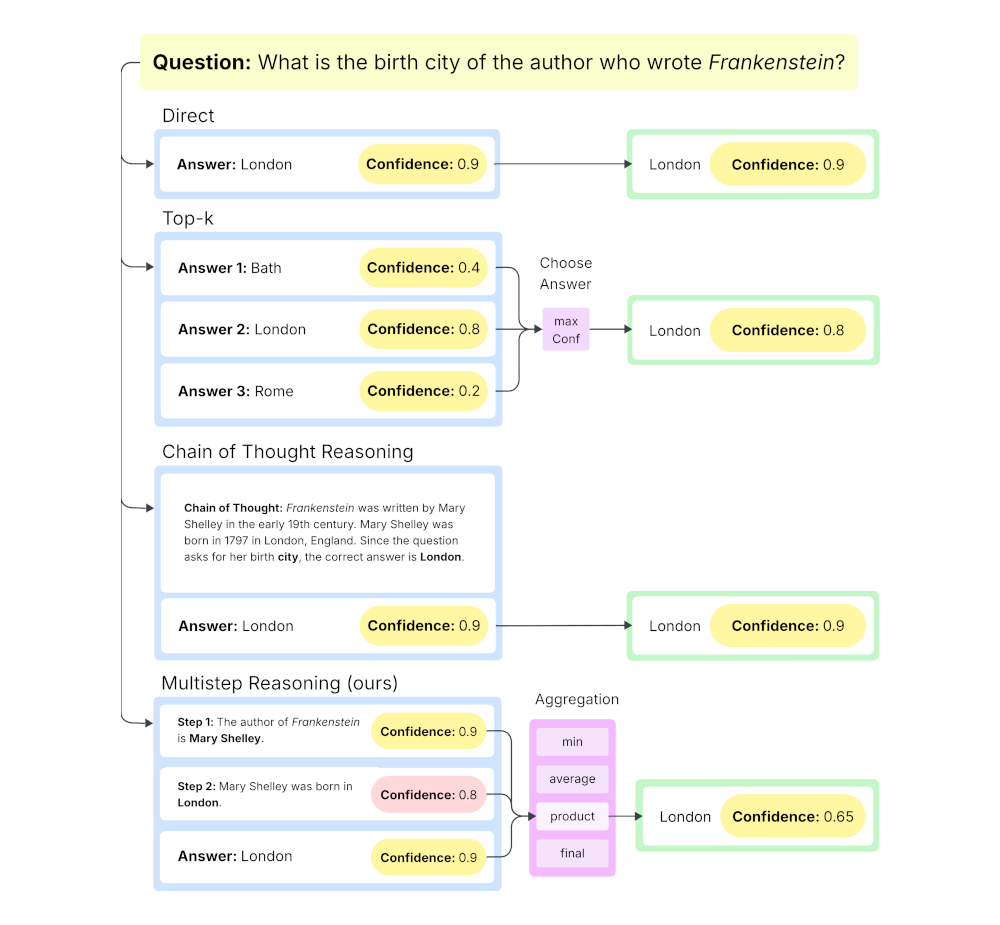
The main idea in the paper is simple:
Instead of asking for one final confidence, ask for confidence at each reasoning step.
This approach, we call Multistep, forces the model to:
- Break reasoning into sequential steps
- Assign a confidence to each step
- Aggregate those confidences into a final score
From the paper:
“It decomposes MHQA tasks, elicits verbalized confidence at each reasoning step… and shows significantly improved calibration compared to existing baselines.”
Why This Works
Think of a reasoning chain like a pipeline:
Step 1 → Step 2 → Step 3 → Final Answer
If any step is wrong, the final answer is wrong.
So instead of treating confidence as a single number, we treat it like a joint probability across steps.
In the paper, the main aggregation method is:
final_confidence = c₁ × c₂ × ... × cₙ
This works because:
- Each step represents a probability of being correct
- The full reasoning chain is only correct if all steps are correct
This simple change already reduces overconfidence significantly.
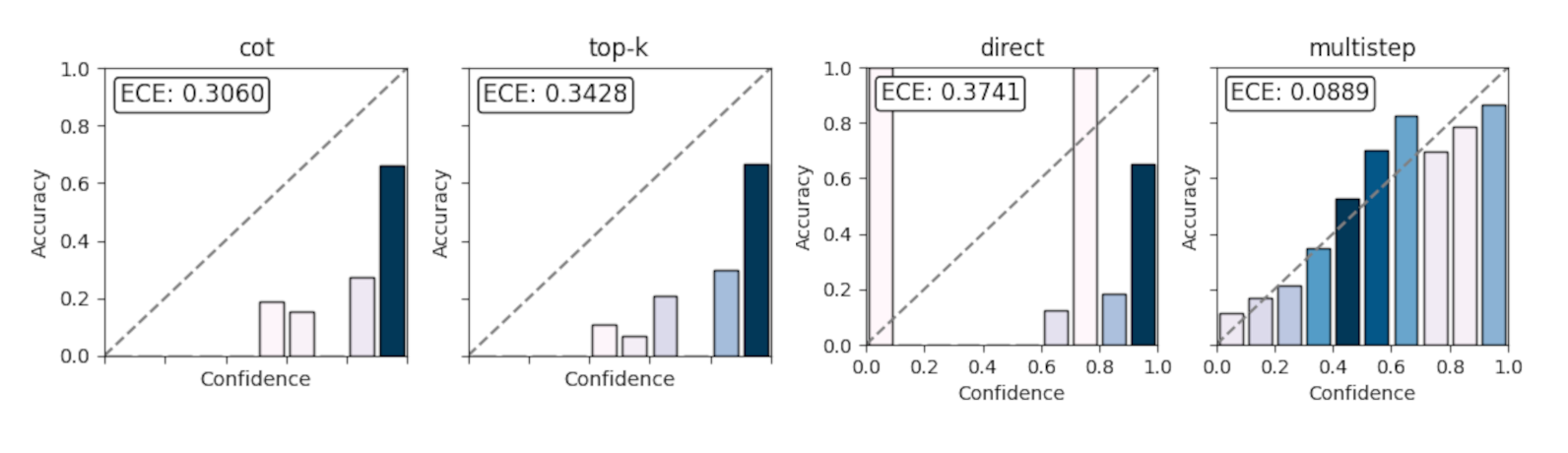
Results: Better Calibration, Same Accuracy
One of the nice things about this approach is that it doesn’t trade off performance.
From the experiments:
- Accuracy: roughly the same as Chain-of-Thought
- Calibration (ECE): significantly better
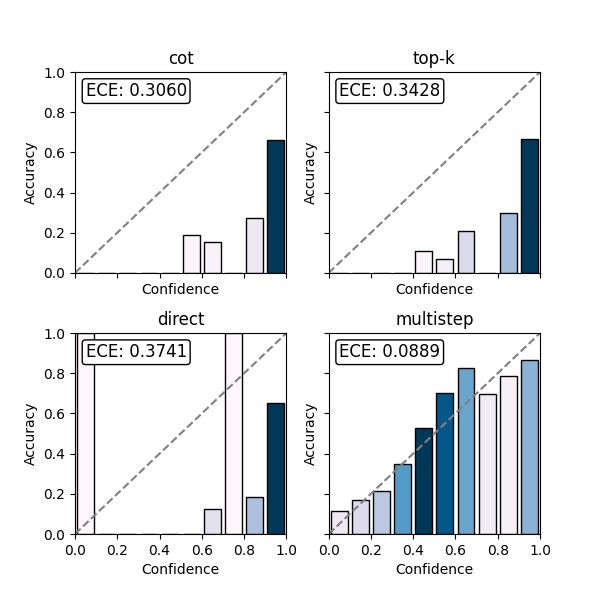
“Multistep achieves substantially lower Expected Calibration Error (ECE)… while maintaining comparable answer accuracy.”
In some cases (like the MuSiQue dataset), the improvement is especially large because that dataset is harder and exposes overconfidence more clearly.
A Useful Side Effect: Finding Weak Reasoning Steps
An unexpected benefit of this approach is interpretability.
Because each step has its own confidence, you can identify:
- Where the model is uncertain
- Which step is most likely wrong
The paper shows that:
- If you take the lowest-confidence step
- And improve it (e.g., with retrieval)
- You get the biggest performance gains
“Using the fact retrieved from the lowest confidence step results in the highest accuracy…”
This suggests a practical workflow:
- Run Multistep reasoning
- Find the weakest step
- Fix or augment it
- Recompute the answer
A Note on Metrics
Evaluating calibration is tricky.
The paper primarily uses Expected Calibration Error (ECE), but also points out an important issue:
- ECE can correlate with accuracy
- A model can look “well calibrated” just because it’s more accurate
To address this, the paper introduces Macro Calibration Error (MacroCE):
- Computes calibration separately for correct and incorrect predictions
- Averages the result
This gives a more stable view of calibration across different scenarios.
Takeaways
The key insight is surprisingly simple:
Confidence should follow the structure of reasoning.
Instead of asking:
“How confident are you in the final answer?”
We ask:
“How confident are you at each step?”
That small shift:
- Reduces overconfidence
- Improves trustworthiness
- Makes reasoning more debuggable
And importantly, it does all of this without modifying the model itself.
Final Thoughts
A lot of work on LLMs focuses on making them more accurate.
This paper focuses on something slightly different:
Making models honest about what they don’t know.
But that’s arguably just as important.
Because in real-world systems, knowing when you’re wrong is often more valuable than being right a bit more often.